Explain why the knowledge area is relevant
Explain why the knowledge area is relevant to your organisation and organisational problem (150/150)
Data Security concerns the policies and practices that aim at data protection in line with privacy and confidentiality regulations that may come from:
Stakeholders: Confidentiality and privacy of the clients' information; everyone in an organization is a trustee of stakeholders' data. Government regulations: Regulations in place that may restrict the access and/or allow openness and accountability. Proprietary business concerns: Each organisation has data to protect, with the potential to provide insight into the business needs and practices, when managed as a value. The lost and inadequate security measures mean a loss in terms of value. Legitimate access needs: There is the need for individuals with key roles to access, use, and maintain data. Contractual obligations: Contractual and non-disclosure agreements are also the part of data security. This context is crucial for students seeking data analysis dissertation help to understand the importance of data security in organisational settings.

(International, 2016)
For the present paper, school x is an organisation with public value and a social mission that is required to follow security data policies and regulations, set by the government, the department for education and international bodies such as the Organisation for Economic Co-operation and Development (OECD).
Data quality points out the need to design, store and access data securely, to share it accordingly and extract the value by learning from it (International, 2017). The lack of understanding of the effects of poor-quality data, poor planning, lack of standards and of governance further contribute to poor quality data, which do not reinforce informed decisions, failing to add value to the organisation. Data quality demands the continuous management of data life’s cycles, measuring it against the standards, set by a data quality team (International, 2017).
Schools' data systems are the backbone, which allow informed decision making and strategic-planning. The vast amount of data gathered from inputs, processes, finances and educational outcomes should enhance school performance by monitoring the effectiveness and increasing accountability (Abdul-Hamid, 2017).
Education Management Information System is a key element of any successful education system. However, developing and managing a school data system can be a challenging task and many countries, despite the increasing investment, still cannot harness the power of data (Abdul-Hamid, 2017).
(word-count 342)
Describe the activities associated with the knowledge area that you’ve undertaken, and the outcomes (500/500)
In terms of Data Security, in line with DAMA-DMBOK, 2017, there is no prescribed way of applying all the required measures, which will guarantee the privacy and confidentiality level needed. Organisations as school x, are interconnected through national and sectoral grid that share common practices and policies. The Department for Education (DfE) has developed in collaboration with key stakeholders. A step by step approach to efficiently implement and develop the culture, processes and documentation needed to comply with the legislation and manage the risks associated with data management (‘Data protection: a toolkit for schools’, 2018). Hence, school x, is responsible to develop their own security policies, in line with national and international regulations, which they abide by such as the General Data Protection Regulation of the EU (GDPR, 2016) and the Data Protection Act 1998. School x also needs to document all the process, by monitoring and measuring their effectiveness against standards set.
School x’s business requirements aim at the education of the public. From an organisational point of view, school x needs to manage:
Students’ academic progress;
Finances; Operations;
From a security perspective it involves the management of personal data concerning:
Students; Parents; Staff; External agencies; Governors;
Following (‘Data protection: a toolkit for schools’, 2018), there is the need to promote awareness about data security risks:
All staff should be aware about their duties in handling personal data; All staff with the authority to create, store and input data, are responsible to know the safe procedures to handle sensitive data; Senior Staff (SLT) is responsible to manage the data ecosystem in compliance with the GDPR and the Data Protection Act;
Organisational chart 1, illustrates school x hierarchical data management responsibilities accordingly with (‘Data protection: a toolkit for schools’, 2018).

(word count – 83)
Following (‘Data protection: a toolkit for schools’, 2018), there is the requirement to create a school’s data map. Figure 2, illustrates how personal data regarding students, is structured and flows, within school x.

(word count 73)
(word count 490)
Data quality points out the need to plan as well as implement and control data management techniques in order to fulfil the requirements of its intended use (International, 2017).
Accordingly, with DAMA-DMBOK, 2017, all data management knowledge areas, contribute to the quality data that support data-driven decision making. However, many organizations fail to define what makes data fit for purpose (International, 2017). Gordon, (2013), stated that, poor quality data can be there due to several reasons:
Databases having inappropriate schemas; Errors being made on data entry; Data decaying over time; Data being corrupted when moved between systems; Lack of understanding of the data when it is used;
DAMA-DMBOK, (2017), suggested that, there is the need to define high quality data. Abdul-Hamid (2017), defined high quality data in schools, as the data that:
Drive system-wide innovations; Promote accountability; Support professionalization; Enhance quality and learning;
In terms of defining a data quality strategy, DAMA-DMBOK, 2017, underlines that, data quality priorities need to align with business strategy. Hence, Abdul-Hamid, (2017), defends that data quality in schools, rests on the development of an Education Management Information System (EMIS). Ensuring that, the education cycles are aligned and the education system is monitored, which is promoting students’ learning achievement and system improvement. Stokes (2018), suggested that, when setting a data system, schools should focus on:
The purpose and use of data are clear and relevant; The precision and limitations are well understood; The amount and frequency of data collected should be proportionate; School and trust leaders need to review processes for both collecting and making use of data once collected;
Continue your exploration of Stakeholder Roles in UK Mega Projects with our related content.
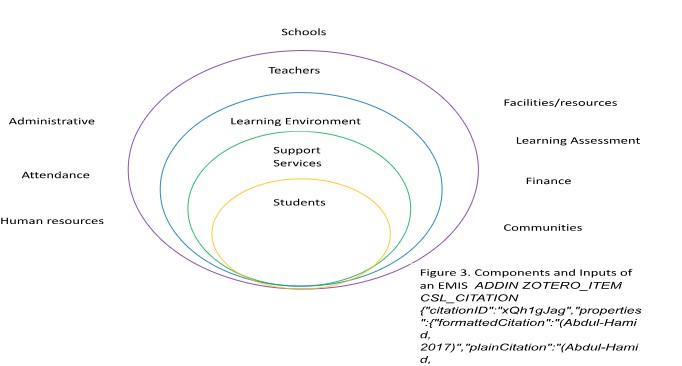
Concerning Critical Data, DAMA-DMBOK, (2017), stated that, not all the data has the same value. Hence, data quality managers need to focus on the data that by being enhanced can bring value to the organization. ‘Data protection: a toolkit for schools’, (2018), suggested that, schools after creating a data map need to turn it into a data asset register. (Abdul-Hamid, 2017), advises that an EMIS should be a credible force for all relevant education data, so that it can promote learning achievement. Figure 3 illustrates the components and inputs of an EMIS, in terms of importance, from the centre to the periphery.
(word count 26)Abdul-Hamid, (2017), continues, stating that, to achieve such high-quality data. A culture of data needs to be established by all the stakeholders across the education system by:
Designing and evaluating policies and standards; Communicating and facilitating resource allocation; Enabling real-time use in classroom instruction; Strengthening school management and planning;

Figure 4, illustrates that, compliance with standards, accountability, and government requirements is no longer enough. Instead, there is the need to move to a data-driven, learning-based education system, where data plays a crucial part across the education system and personalised learning analytics that are used in the classroom.
Evaluate the effectiveness of the activities that you’ve undertaken, and outline any appreciable changes or improvements you would apply if you were to do it again.
Concerning Data Security, the activities taken focused on describing the Data Security measures in place at school x. School x Data Protection Policy (DPP), describes in what way it is aligned with the GDPR and the Data Protection Act. School x DPP document presents how all data must be:
Processed lawfully, fairly and in a transparent manner; Collected for specified, explicit and legitimate purposes; Adequate and relevant; Accurate and, where necessary, kept up to date; Kept for no longer than is necessary; Processed in a way that ensures it is appropriately secure;
However, the technological aspect of the DPP, this is, how it is implemented, is not contemplated in the document. Given the present circumstances, it was not possible to carry extensive personal interviews with the senior leading team (SLT). It is also useful to understand that the SLT, being responsible for reviewing processes for collecting and use of data. It is not expected to understand the technological aspect of it. Hence, the activities were limited by researching governmental/official documents concerning data security in schools, referencing the approach taken with the DAMA-DMBOK, (2017). It suggests a step-by-step approach on how to implement such measures, allowing schools to decide the technological means for such, as long it is in line with national and international policies. These circumstances, limited the understanding retrieved from the activities, not allowing seeing the big picture. For example, how the different data security measures adopted by schools in the UK, affect the data quality from a national point of view?
Regarding Data Quality, the activities taken aimed at understanding the process adopted by school x to ensure data quality. Given the present circumstances was not possible to carry on extensive interviews with the SLT responsible for reviewing processes for collecting and using the data. However, from the informal short talks carry on with some SLT, was possible to observe that the concept of quality data is not fully clear. Most schools nowadays, in terms of data, still have as main concern, coping with national and international data policies, mostly regarding Data Security. Data Quality requires an in depth understanding of data management in all its extension and potential. Task that schools are not yet equipped to fully grasp. Hence, the activities taken, aimed at understanding what is meant by school data quality and how to achieve it by researching the papers that approach the topic and referencing the approach taken with the DAMA-DMBOK, (2017).
A description of the key distinguishing characteristics of ‘Big Data’ along with an explanation of why this topic is of relevance to the data management community and (if applicable) to your organisation. (200)
Following the description by (OU, 2021), Big Data (BD) concerns the technology and processes that arise from the capacity to gather and analyse large amounts of data from different sources. Hence, Big Data denotes variety, in terms of structured and unstructured data, such as video, audio, documents, etc; the velocity that it is gathered and the volume of it (Laney, 2001) cited by (Clarke, 2016). Other authors have also added value as a fifth characteristic (Clarke, 2016). Accordingly with DAMA-DMBOK2, the advent of BD has prompted the research of Data Science methods that allow a forward-looking, “windshield” view of the organisation. Until then, Traditional Business Intelligence was only able to support a “rear-view mirror” of past trends. This means that, it lacks the methods to provide real-time and model-based, which offer predictive competences to an organisation (International, 2017).
With the enormous flow of data produced by the rise of social media, Internet of things (IoT) and multimedia are important (Hashem et al., 2015). BD has become of great importance to the data management community because it implies a disruptive change on how data is gathered, stored, accessed and processed, having repercussions in all the Knowledge Areas concerning data management (International, 2017).
Correspondingly, BG is also having a big impact for the organisation selected: school x. As mentioned by (Cope and Kalantzis, 2016), BD comes with the promise to revolutionize the teaching and learning process by allowing more personalised educational plans, a continuous formative, real-time assessment and a wider collaborative learning.
A summary of each article. (300/300/300)
Clarke (2016), Big Data, Big Risks
Addressing some of the problems that come from the present exacerbated optimism around big data and the risks often shadowed by it, the article starts by introducing Big data as a product, which originates from the development of sensor and storage technologies with the potential to be interrelated and analysed critically. The author mentioned the three Big Data “Vs” – volume, velocity and volume, and points out the “value” and “veracity”, added by some researchers. The study points out the study by (Anderson, 2018) that defends that with the advent of BD and the potential to retrieve knowledge from it by applied mathematics, the scientific method and all the sciences become obsolete. The study starts by defining BD Quality given the high risks imposed by the exacerbated optimism around BD. It distinguishes two primary quality categories:
1 - Data quality (DQ): possible of being assessed when data is collected; and within DQ:
Syntactic validity; Appropriate entity association; Appropriate attribute association; Appropriate attribute signification; Accuracy; Precision; Temporal applicability;
2 - Information quality (IQ): not possible to assessed until data is used; and within IQ:
Theoretical relevance; Practical relevance; Currency; Completeness; Controls; Auditability;
The author then presents several scenarios, where it highlights the above DQ issues. Underlining these are not case studies but “plausible stories”.
Fraud detection; Creditworthiness; Foster parenting; Precipitation events; Ad targeting; Insider detection; Cancer treatment;
The study then concludes by describing some professional association good practices code. Highlighting as a good example, the Association for Computing Machinery Code for Ethics and Professional Conduct provide ethical codes (ACM, 1992). Some of the points described are:
Contribute to society and human well-being; Avoid harm to others; Be honest and trustworthy;
The author finishes, underlining the responsibility that computer scientists, academics and data management professionals have for the technical aspects of data collection, storage and access. By making use of risk assessment, ensuring that business processes have in place safeguards, compliance audits and enforcement activities.
Cope, B. and Kalantziz, M. (2016), Big Data Comes to School: Implications for Learning, Assessment, and Research
Discussing the Big Data potential in Education by studying the data generated by writing, the authors justify writing as their choice due to the nature of it as evidence of knowledge cross curriculum. The authors start by describing some of the promises and concerns around BD in Education. From personalized teaching, live formative assessment and collaborative learning. In order to maintain data privacy, intensification of didactic pedagogies, test-driven teaching is effective to invasive teacher accountabilities regimes. The study then offers a short description of what it means BD in Education:
The high volume of data generated by digital learning environments; The varied types of data that are recordable and analysed; The accessibility and durability that allow a continuous formative assessment and the creation of learners’ profiles and longitudinal analyses; Data analytics that prompt the development of educational software, institutional accountability and educational research;
The authors then introduce the field of education data science that can be divided into:
Educational mining – more focused on unstructured data such as log files, keystrokes, clickstream data, etc.; Learning analytics – more focused on structured data such intelligent tutors, games, rubric-base peer review, etc.
In terms of Evidence of Learning in Computer-Mediated Environments, the study sets these into three major categories:
Machine Assessment: . Computer Adaptive Testing – Select response assessment; Structured, Embedded Data: . Natural language processing – Automated essay scoring; . Procedure-defined processes – Intelligent tutors; . Argument-defined processes – Rubric-based peer review of writing; . Machine learning processes – Semantic tagging and annotation; Unstructured, Incidental Data: Incidental “data exhaust” – keystrokes patterns, navigation paths; . Collection of unstructured data – video capture, movement detectors; The authors also distinguish between two assessment models:
Traditional: The assessment is external to the learning process;
. Limited data sets; . Summative assessment; . Expert assessor;
Emerging: The assessment is embedded in the learning process;
Big Data; . Feedback is recursive; . Crowdsourced;
In terms of Education Data Science, the study compares Traditional to Emerging Models of Research.
Traditional Research Model:
Researcher as an independent observer; Optimal sample N to produce reliable results; Fixed time frames; Standardization of results; Division between qualitative and quantitative research;
Emerging Research Model:
Subjects as data collectors; Sample can be: N= all and N= 1; Short time frames; Heterogeneity in data; Integration of quantitative and qualitative research;
Take a deeper dive into Experience, Expertise, and Dedication with our additional resources.
In terms of research and Data Infrastructure the study also distinguishes between Traditional and Emerging Data Infrastructures:
Traditional:
Journal articles and monographs; Meta-analyses are based on results as reported; Divergent data models; Research ethics protocols based on consent prior to research;
Emerging:
Full data sets; Meta-analyses can mine multiple data sets; Data standards support interoperability of data; Data collection and instruction are integrally related;
The study concludes by stating that much work still needs to be done in the field of big data and education data sciences. Before the potential of computer-mediated learning can be fully realized in educational practice.
Hashem, I.A.T. et al. (2015), The rise of “big data” on cloud computing: Review and open research issues
It is effective discusses the relation between cloud computing (CC) and BD, BD storage systems and Hadoop technology. The study also focuses on scalability, availability, data integrity, data transformation, data quality, data heterogeneity, privacy, legal and regulatory issues and governance. The authors describe the four characteristics of BD:
Volume*; Variety*; Velocity*; Value*;

The authors mention that the high growth of data makes it difficult for researchers to develop CC platforms for data analysis and update intensive workloads. One of the solutions is the adoption of Hadoop clusters provided by vendors such as IBM, Microsoft Azure and Amazon AWS.
In terms of BD classification, the study details five aspects:
Data sources*; Content format*; Data stores*; Data staging*; Data processing*;
Regarding CC, the study points out three different models:
PaaS*; SaaS*; IaaS*;
In terms of data sources, the study describes:
Social Media; Machine-Generated data*; Sensing*; Transactions*; IoT*;
In terms of BD content:
Structured*; Semi-structured*; Unstructured*;
Regarding data stores:
Document-oriented*; Column-oriented*; Graph database*; Key-value*;
About data staging:
Cleaning*; Transform*; Normalization*;
Concerning data processing:
Batch*; Real-time*;
The study then focuses on the relation between CC and BD, referring that while BD allows to process queries across multiple data sets. CC provides the engine through the use of Hadoop*, while data visualisation, provides an analytical view of the results. The study then represents tables and descriptions comparing some BD cloud platforms*; related studies about BD and CC*; and Organisations case studies from Vendors*.
In terms of BD storage, the author presents a table, which compares different storage media. Reporting that existing technologies can be described as:
Direct attached storage (DAS); Network attached storage (NAS); Storage area network (SAN)
The authors then describe Hadoop technology as an open-source Apache Software Foundation project written in Java that allows the distributed processing of large datasets across clusters of commodities. The two primary components Hadoop are HDFS and MapReduce, co-deployed such that a single cluster is produced. The study presents tables regarding Map Reduce projects and SQL interfaces in the MapReduce framework*.
The study then focuses on some of the research challenges:
Scalability*; Availability*; Data integrity*; Transformation*; Data Quality*; Heterogeneity*; Privacy*; Legal/regulatory issues*; Governance*;
Concerning open Research issues:
Data staging*; Distributed storage systems*; Data analyses*; Data security*;
The study concludes by highlighting that the challenges and issues must be addressed, ensuring the long-term success of data management in the CC environment. (word count- 404)
A comparison, contrastive analysis and evaluation of each article’s contribution to assessing the impact of ‘Big Data’ on the knowledge areas defined by the DAMA-DMBOK Data Management Framework (300/300/300)
The article by Clarke (2016), addresses some of the problems that come from the exacerbated optimism around big data and the risks often shadowed by it.
The study by Cope and Kalantzis (2016), discusses the Big Data potential in Education by studying the data generated by writing. The study by (Hashem et al., 2015), discussed the relation between cloud computing (CC) and BD. Focusing on scalability, availability, data integrity, data transformation, data quality, data heterogeneity, privacy, legal and regulatory issues and governance. Data-Governance highlights the organisation's need to manage data as a valuable asset (International, 2017). The study by Clarke (2016), describes some quality risks that BD analytics introduce in terms of data management, expressed on the question: “what risks arise from inadequate attention to quality in BD and BD analytics?” This can be understood as: what are the implications for Data-Governance with the introduction of BD and BD analytics. The article by Cope and Kalantzis (2016), discusses in what way BD and BD analytics can enhance teaching and learning by adding value to the data gathered from writing as a cross curriculum activity. This is, as knowledge evidence. The study by Hashem et al. (2015), as clear inferences in Data-Governance by highlighting that a valid data policy has to be in place concerning the type of data that need to be stored and how to access it.
DAMA-DMBOK describes Data-Architecture as the effective management of data, systems and data storage (International, 2017)
The study by (Clarke, 2016), does not explicitly focus on Data-Architecture. However, it addresses the quality risks that arise from the consolidation of data from multiple sources, inferring this way, the issues concerning Big-Data- Architecture. The article by Cope and Kalantzis (2016), focus on the potential enhancement from the introduction of BD, BD analytics and Data mining in Education, by discussing the implications in terms of data access and sharing and so, in terms of Data-Architecture. The study by Hashem et al. (2015), addressed the relation between BD and CC that implies a change in Data-Architecture compared with more traditional methods.
Data Modelling and Design is defined by DAMA-DMBOK as scoping and communicating data in a precise form called the data model.
The study by Clarke (2016), focuses directly on the risks associated with BD and BD analytics due to the quality factors not being addressed properly, and so missing the aim of Data Modelling and Design. The article by Cope and Kalantzis (2016), discusses the implications of the introduction of two new subdisciplines of education: educational mining and learning analytics. Learning analytics refers to structured data, which includes data models and so concerns Data Modelling and Design. The study by (Hashem et al., 2015), addresses Transformation and Quality as two of CC/BD issues, both concerning modelling data into a form suitable for analysis.
DAMA-DMBOK describes Storage and Operations as the design, implementation and support of stored data to maximise its value.
The study by Clarke (2016), describes several scenarios where issues about BD can arise. Scenario 3, discusses the problems about how data is collected, involving data compression and so, it is understood, how data is stored and the problems concerning Accuracy and Completeness.
The article by Cope and Kalantzis (2016), does not address directly how data is stored. However, by focusing on the different types of data emerging from technologies-mediated learning environments, It implies the data lifecycle from database environment implementation, through obtaining, backing up and purchasing (International, 2017). The study by Hashem et al. (2015), highlights BD/CC storage as one of the open research issues, due to the increasing amount of data gathered at an exponential time vs the slow improvement in the processing mechanisms.
Data security is defined by DAMA-DMBOK, as the process that ensures data privacy and confidentiality.
None of the scenarios described by Clarke (2016), focused directly on Data security. However, scenario (2) Creditworthiness, describes the problem that arises when financial services providers correlate data from transactions, fraudulent transactions and government statistics about geographical distribution of wealth. The author points out the discrimination risk based on the behaviour of third parties. This way, discrimination as presented, can be understood as a breach of data privacy and confidentiality. The article by Cope and Kalantzis (2016), briefly mentions data privacy as one of the challenges within educational data science. In traditional infrastructure, the research ethics is based on consent prior to research. Contrasting with mining historical data, where data collection and instruction are integrally related. The study Hashem et al. (2015), highlighted privacy as one of the concerns regarding BD/cloud storage. This is due to big data mining and analytics requiring personal information to produce pertinent results. It also underlines data integrity as a BD security risk, meaning that, there is the need to ensure that the data can only be modified by authorised personnel.
Data integration and interoperability is defined by the DAMA-DMBOK, as the process of data consolidation between databases, applications and organisations.
The scenarios suggested by Clarke (2016), apart from scenario (1) – Fraud detection and scenario (7) – Cancer treatment. Focus on the risks of inept data consolidations between databases, applications and organisations, which result on data and information quality issues. The study by Cope and Kalantzis (2016), focus on the potential of BD in Education, collected through different modes that entail the consolidation of diverse data types, such as: Machine Assessment; Structure embedded data and unstructured incidental data. The article by Hashem et al. (2015), investigates the status of BD in CC. Starting by defining BD in terms of: Volume; Variety; Velocity and Value. Variety is defined by data collected via different applications that will require the consolidation of various data types.
Reference and master data are defined by the DAMA-DMBOK – as the maintenance of critical shared data to enable consistent use across systems.
The scenarios suggested by (Clarke, 2016), highlight data and information quality issues that may arise when a valid Master Data Management program is not in place.
Metadata is defined by the DAMA-DMBOK – as the planning, implementation, and control activities to enable access to high quality, integrated metadata.
The study by Clarke (2016), focused on data and information quality issues that may arise from data integrity problems due to metadata loss.
Data quality is defined by the DAMA-DMBOK – as the planning and implementation of quality management techniques.
The article by (Hashem et al., 2015), discusses that BD, involves the use of sources not verifiable, resulting in poor data quality.
The study by (Clarke, 2016), focuses directly on data quality factors that depend on:
Syntactic validity; Appropriate (id)entity and attribute association; Appropriate attribute signification; Accuracy; Precision; Temporal applicability;
Information quality factors are such as:
Theoretical relevance; Practical relevance; Currency; Completeness; Controls; Auditability;
(word count - 1121)
A discussion of the extent to which the ideas set out in the articles might or might not be used to change policy and/or practice in data management, along with suggestions as to how any change might be incorporated. (200)



- 24/7 Customer Support
- 100% Customer Satisfaction
- No Privacy Violation
- Quick Services
- Subject Experts