NLP in Social Media Analysis
1. Introduction
The number of social media investigations using Natural language process (NLP) and Machine Learning (ML) for text analysis has been increasing rapidly (e.g. Lin et al. [1], Misirlis and Vlachopoulou [2], Mart´ınez-Rojas et al. [3]). Promoting the content of social media is affected by several artifacts. The most important artifacts are trust Cheng et al. [4] and quality Casal et al.[5], which are directly influenced by the text complexity Pogrebnyakov and Maldonado [6]. The features of texts were examined as early as 1948’s Flesch [7] in various domains. The goal is to formulate text to fit the age and reading skills of a target group’s category. For example, in educational field, it is important to generate text with a level that is suitable to the students’ class level Schwarm and Ostendorf [8]. The feature extraction rests on various approaches, e.g. syntactic, vocabulary, coherence, cohesion, discourse etc. and applied various arguments or features, e.g. Text parse tree height, bag-of-words based on word frequency, cosine similarity, information ordering etc. as introduced in Schwarm and Ostendorf [8], Barzilay and Lapata [9]. Depending on the type of text, some features perform well and are therefore correlated with e.g. readability and some are not.It is obvious that, in depth meaning, easy to read, well-formatted structure, error free in grammar and more, are characteristics of qualitative text. These can be measured using readability indexes and natural language processing (NLP) approach to analyze Part-of-Speech (PoS). The major aim is the transmission of high quality information, whereby the topic and target group are limited or already given. However, in the context of social net- works as Genius1, Stackoverflow2 or Twitter3 these are very broad or even not known. . It is appropriate to clarify the challenges involved in investigating their contents when it comes to use traditional machine learning techniques, especially social media, which are in focus for our work.
The social media Genius allows text interpretation in the form of annotations on various topics. Annotations are the interpretation placeholder and these provide metadata such as authorship, reader rating and suggestions. The Genius users are distributed into six roles (Whitehat, Artist, Editor, Mediator, Contrib- utor and Staff or Regulator) that are assigned different permissions (more details in our technical report Al Qundus [10]). The Interpretations are free (un- structured) short texts that are unlimited and can contain pictures, links (URLs and cross-references) and symbols. Numerous examinations on text mining He et al. [11], Rekik et al. [12], Gandomi and Haider [13] and short text exist. Solka et al. [14] investigate short data mining for information extraction on the basis of the principles of NLP (stemming, tokenizing, N-grams and bag-of-word) for applying clustering tasks (term frequency inverse document frequency). Chalak [15] examine the linguistic and discoursal characteristics (short cut, co-language, slangs, symbols etc) in massages to predict the authorship (male or female). Short text clustering in social media is an increasingly application investigations. Jia et al. [16] determines the community semantic words to create semantic concept vectors, to which short texts are mapped to identify their cluster. Sriram et al. [17] apply a short text clustering and introduce an information filtering approach for tweets. Vijay and Rao [18] propose a tweet segmentation system that splits short text into semantic expression in English i.e., worldwide setting or setting data expression inside the clump of tweets i.e., nearby setting. Rao et al. [19] extract the user preferences to improve marketing strategy development by classification of emotion in short text. Since the short texts are usually created in an intimate and natural way, they are valuable for deriving user needs. In addition, since NLP is not suitable for short texts and therefore the results obtained are inaccurate, the necessity for adapted methods has become urgent. The information, gained from short texts, can be used to support and improve search/filtering engines, preferences prediction (marketing), knowledge sharing, vandalism and fake news recognition etc. for which identification of high quality short texts and their transmitting in such a way, that human being can understand, are essential.
The aim of this work is to present our approach in progress and to discuss the promising initial results of examination quality of short texts. These can either be transferred to social collaboration such as Wikipedia or Yelp etc., or form the basis for it.
2. Related Work
This section introduces the works that inspire our approach. Barzilay and Lapata [9] propose an entity-based statistical model that examines entity coherence and lexical cohesion elements, for e.g. the number of pronouns or definite articles per sentences to qualify topic continuity from sentence to sentence, average cosine similarity and word overlaps. The authors reported good results, for e.g. more entities and more verb phrases reduce readability. The operation case of this work is a corpus as a whole. This is indeed an essential first step towards gaining a vision about the distribution of text properties. However, our purpose is to put subsets or even individual short texts in competition. The work addresses also that so called ranking problem -text ordering and summary evaluation-, which is difficult to apply on short texts. Todirascu et al. [20] examine various cohesion aspects to investigate readability of the short text. The authors extend the texts with the corpus as external knowledge to manually annotate on the texts. We adopt some of the features used, e.g. the Entity density and plan to deploy the co-reference chain properties. This approach uses a corpus that originates from a specific topic (French as a foreign language), whichsimplifies the annotation process but cannot be applied in the context we address. Unlike most approaches to explore the similarity of documents, Hatzlvassiloglou et al. [21] approach acts similarity at the level of text parts (paragraph- and sentences-level). Each text part is a representative of the action contained in the original text. Accordingly, dealing with such text parts is more difficult, because the smaller the text, the less likely it is to identify the matches between the words on which the measurement of similarity is based. The work provides composite features that are pairs correlations of primitive features such as noun phrases and semantically similar verbs. A machine learning method for mapping the feature values into a similarity measure. The work suggests a text summarizing approach, since we are interested more in the semantically similar grammar, we can modify the technique used and adopt it for our purpose. For example, they calculate the semantic distance between phrases, we can use the same calculation to evaluate the distance of the number of relation triples (subject-verb-object) that occurs in the sub sets in consideration. Heilman et al. combine (1) grammer- (using a classi- fier - identifying features, algorithm applies the features and a component for training data) and (2) vocabulary (patterns of use) model-based approaches to predict readability of first and second language texts. The authors stated

that, these approaches are suitable for web documents and short texts Heil- man et al. [22]. In addition to this, Heilman’s et al. approach, Pitler and Nenkova [23] combine discourse feature to predict, but in this case, the quality of the text. Even if discourse relations based on vocabulary are not so important, we were still interested in this work, due to the wide array of the characteristics examined. In this work, reader rated (readability measure) journal articles selected from the Wall Street Journal corpus. The authors tried to restore the results of the rating by calculating the likelihood of an array of the features and using a linear regression to measure the features of correlation. The last two works are the closest to our work with the differences of context (social network), audience (open), text type (short text, interpretation), focus (quality leads to trust), features (fitting to all previous ones) and the way we divide the corpus into four segments to be investigated.
3. Background
In this section, we introduce our trust model used for the basis-classification, the machine learning technique applied in this paper, and the computational theory behind such technique, briefly.
3.1. Trust model
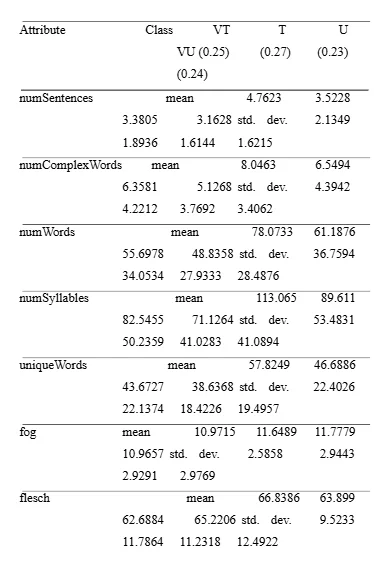
In our prior work Al Qundus and Paschke [24], we developed a trust model that classifies Genius annotation into four classes (Very Trusted, Trusted, Un- trusted and Very Untrusted) as shown in Table 1. These classes were created on the basis of the Empirical Cumulative Distribution Function (ECDF) and the manual observation of the database analysis. The model consists of three dimensions, categorized based on the meta data metrics of the annotations. These dimensions are 1) Stability, which is calculated based on the number of edits of annotations over a period of time. 2) Credibility is based on user ratings and activity type, and 3) Quality depends on the profiles of authors and editors. Each dimension has a weight that is calculated on the basis of the measure of the user preferences. These measures and their weights give a trust degree of an annotation, which is then assigned to one of the trust classes.
In this paper, however, we hold the same classes, in its place; we propose a new approach that classifies these instances based on the content (text) using the Random Forest technique.

3.2. Random Forest (RF)
According to Klassen and Paturi [25], random forest is a meta-learner, which consists of a collection of individual trees (logical conjunction of disjunctions). Each tree votes on an overall classification for the given set of data. The random forest algorithm decides to select the individual classification with the most votes. Each decision tree is created from a random subset of the training data set, using that so called replacement, in performing this sampling. That is, the entities contained in a subset for building a decision tree are possible candidates of the next subset for creating the next decision tree, which leads to that some entities, are included more than once in the sample, and others won’t appear at all. While building each decision tree, a model based on a different random subset of the training data set and a random subset of the available variables are used to select how best to partition the data set at each node. Each decision tree is designed for its maximum size, with no pruning performed. Together, the resulting decision tree models of the random forest represent the final ensemble model where each decision tree votes for the result, and the majority wins. In order to evaluate the performance of the RF classifier, a set of the following measures are considered:
(1) sensitivity (SE) which represents the true positive rate,
(2) specificity (SP) which represents the true negative rate (complement of sensitivity),
(3) precision (PR) which represents the ability of correctly predicted positive target condition to the total,
(4) accuracy (ACC) represents the classifier ability to predict the target condition cor- rectly,
(5) F-measure (F-measure) represents the classifier ability to predict the target condition correctly (comparing to ACC, it tells a lot more in case of imbalanced date set, since it considers both PR and SE),
(6) the Matthews correlation coefficient (MCC) which indicates the correlation degree of the tree decisions; according to the following formulations:

Where,
TP is the number of true predicted positives
TN the number of true predicted negatives
FP the number of false predicted positives
FN the number of false predicted negatives
This work uses the RF from the platform KNIME Berthold et al. [26] with the following parameters and options:
num Trees which consists of defining the number of trees to generate (equals 100).
Seed which means the random number seed used (equals 1).
Num Execution Slots (1) means the number of execution slots (threads) to use for constructing the ensemble.
maxDepth (0 for unlimited) means the maximum depth of the trees.
numFeatures (0) means the number of attributes used in random selection. The next section describes the workflow applied.
4. Approach
Our approach is novel in addressing the problem of trust classification based on the content solely and without text manipulation. In the following we describe in more details our approach.
4.1. Application Natural Language Processing (NLP)
In order to identify the rules of the quality relation in each class, we investigate the correlation of various readability indexes and syntactic constructions. Using 20% of the data sets, we tested the average number of sentences, words, characters, complex words, syllables, unique words, words per sentence, syllables per word, part-of-speech and the readability indexes KINCAID, FOG, SMOG, FLESCH, COLEMAN LIAU and ARI.
4.1.1. Experiment
For this experiment, we build multiple-class classifiers that are Random Forest, Decision Tree and Naive Bayes. Decision Tree did not perform well compared with Random Forest and Naive Bays, which have achieved similar accuracy. This accuracy resulted based on Naive Bayes with the test mode of 500-fold cross-validation using tool weka-3-8-2. Listing 2 summarizes the run information applied. The multiple-class classifier of Naive Bayes achieves 34% accuracy, which is considered as a good performance towards dealing with short-text against four classes.


Listing 2 shows the statics of the experiment and Listing 3 represents the confusion matrix of the classifier, which performs well in recognition the instances of very-trusted short-text (VT:105) and very-untrusted short (VU:114) compared to the instances of untrusted short-text (U:71) and trusted short-text (T:11). These are good classification results considering the challenge of short-text multiple classifications. Nevertheless, this irregularity only allows determining a pattern with increasing or decreasing properties toa limited extent. Thus, hardly a single generalization can be enforced across all the classes. The Figures [4 to 13] visualize and Listing 3 represents the features investigated in order to train a classifier to categorise the short text. From these figures and listing, we can see that, some of the features have a linear verity over the four classes. For example, considering the feature numWords (means and 78.0, 61.1, 55.6 and 48.8 of the classes VT, T, U and VU respectively) that could be applied as a good metric in order to classify short-text regarding trust. While the feature numSentences (means of 4.7, 3.5, 3.3 and 3.1 ) is less of analytic quality and the feature wordsPerSentence (17.1, 18.19, 17.7 and 16.3), that is even inexpressive.

4.2. Machine Learning Techniques
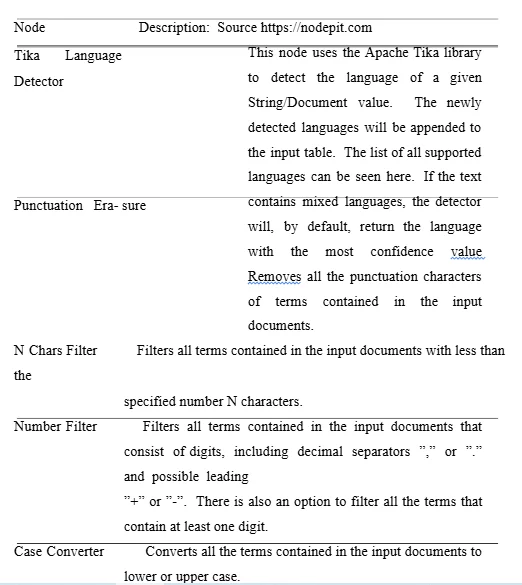
Pre-processing Machine learning algorithms perform poorly in working on texts in their original form. The corresponding form represents a vector of numerical features. Therefore, a pre-processing step is necessary to convert the texts into a clearer representation. The text segmentations of the classes are cleaned using the following tasks (see Table 4): Punctuation Erasure, N- chars Filter, Number Filter, Case Converter (lower case), Stop-words Filter, Snowball Stemmer and Term Filtering. We used a language detector, provided

The output of this stage is a new file represented in a vector space based on the bag-of-words model (BoW) combined with Term-Frequency (TF). The representation is actually 1 if the word is present and 0 otherwise. The TF is the number of times a word appears in the instance (text). We first experiment with the effect of changes in random forest’s parameters on its performance. The number of trees to be generated numTrees was set to 10, 100 and 150. The number of tree depth was set to 10 and then to 0 to create trees of any depth. The number of runs (loop) was set to 10, 100, 150 and 1000. Within each run, the data is split again into training and testing data and at the end of the loop the average on measures is calculated. For all data sets, the RF performs stable on the numTrees equals 100, unlimited tree depth (0) and the loop size of 100. Model Building The classifiers were trained and tested, with the division into 80% training data and 20% test data from the data generated by
the pre-processing phase. The data sets used by the classifier are imbalanced (see Table 1), which can influence the classifier to the advantage of the set with more samples and is so called the problem of the imbalanced class distribution. We have applied an under-sampling approach that reduces the number of samples of the majority class to the minority class, thus reducing the bias in the size of distribution of the data subsets. Negative and positive examples were forced to equal amounts when performing a 100-fold Monte Carlo Cross Validation (MCCV) Xu and Liang [27] for a model setup. This data was resulted by merging each two-trust class into one corpus in order to conduct binary-classification. For the feature extraction, we use the bag-of- words model, which scans each class to build a collection of words presented and sum up their frequency. This bag-of-words is then used to calculate Term Frequency (TF) that indicates the similarity degree between a text and a document, in our case; these are an instance and a trust class. The resulted combinations are recognized in the Table 5.
4.2.1. Illustrative Example
We shall prepare a file containing the trust classes very trusted (vt) and very untrusted (vu) for processing. In the pre-processing phase, two file readers load the classes vt and vu in their raw form independently . Each class is converted into a document, marked with its class label. After other languages have been removed and only English texts have been stored by a Tike language detector, the two classes are merged into one file (vt vs vu) via a concatenation node. This file passes through several nodes, including cleaning steps as represented in Figure 1.

This figure illustrates the workflow applied for the short-text analysis. It consists of two phases: Pre-processing phase, on the left side, and the learning stage On the right side. Now we get a clean document and term frequencies as a matrix table, based on which a binary vector can be created with a document vector node. The final step is to write the output file containing in each row of the text of an instance, keywords and their frequencies, and the trust label. In the processing phase, the generated file is forwarded to the row filter node to remove rows within a text length of less than 10 words. A column filter isolates the keywords, their frequencies, and labels, and then passes the file to a count loop node. In each loop, the samplings included in the file is equalized (under-sampling) and split randomly into training subset to create the decision trees and testing subset for the prediction by the learning algorithm (RF). In the prediction phase, the RF applies the testing subset over the generated decision tree models and represents its performance measures. At the end of the loops (100 runs), only the average on the several performance measures, which should be stable now, is considered.
5. Results
This binary-classification is our reference for the short-text mining that aimed at in this work. The classifier developed must be able to restore this classification with the best possible accuracy. According to our logic, Very Trusted class must contain more texts of higher quality than Trusted class, which contains more texts of higher quality than untrusted class, and this class contains more texts of higher quality than very untrusted class. We can see in Table 1, the number of instances per Trust class is imbalanced. Very Trusted class of Genius and Trusted class of Stackoverflow are more biased towards other classes. It is desirable to have a classifier that offers high prediction accuracy across all classes. This is a challenge and can be bypassed by binary classification. Our novel work on interpretations could have a different perspective, for example, than Pitler and Nenkova [23], who found that ”longer articles are less well written and harder to read than shorter ones”. This can be the opposite in the case of interpretations. As a rule, longer descriptions provide the necessary explanation. Under this assumption, this work carries out natural language processing (NLP) i.e. part-of-speech and several readability indexes as well as a machine leaning technique (ML) based on bag-of-words model applied by the random forest classifiers. The aim is to evaluate the interdependence of the features and their influence on quality. The NLP analysis results that, there is a linear relation between quality of text and the metrics present 3rd person singular (VBZ), present tense (VBP), base verb (VB), adverb (RB), possessive marker (POS), common noun (NN), adjective (JJ), gerund, present participle (VBG), past tense (VBD), plural common nouns (NNS) and plural proper noun (NNP) (see Figure 2). This linear relation exists also within the metrics number of characters, number of words, number of syllables (see Figure 3). While such relation could not be found in terms of readability indexes and it is limit regarding the number of complex words. However, the results of the random forest technique based on the bag-of- words model look much more promising. Table 6 gives an overview on the percentages of the factors considered. The best classifiers performances are applied on the combinations of (very) Trusted versus (very) Untrusted, while the worst performances can be found on the combinations, which are close to each other (Very Trusted vs. Trusted and Untrusted vs. Very Untrusted). This is represented by vt, vs and t.

(57%, 57% and 61%, 62% as F-measure and ACC of Genius and Stackover- flow respectively) and vu vs. u (54%, 55% and 57%, 53% as F-measure and ACC of Genius and Stackoverflow respectively), in contrast to higher performances in case of all other combination, mostly. For example, the highest distance can be found in the combination of vt and vs. vu is an evidence of their dissimilarity (69%, 68% and 70%, 66% as F-measure and ACC of Genius and Stackoverflow respectively). This is confirmed by the highest MCC7 measure of each combination and applied in both online communities and indicates the correctness of trust classification. Considering the measures sensitivity and specificity, we can see that, the classifiers are more able to correctly classify instances as (very) Trusted in contrast with (very) Untrusted, in case of Genius (at highest 70%), while in- stances as (very) Trusted in contrast with (very) Untrusted, in case of Stack- overflow (at highest 80%). This indicates the ability to recognize trusted in- stances, which differ from each other based on their content from other. On the other hand, in case of Very Trusted merged with Trusted versus Very Untrusted merged with Untrusted (vtt vs vuu), the true recognition of negative instances (very untrusted merged with untrusted vtt) is higher (66% and 64% of Genius and Stackoverflow respectively). This indicates that despite the proved dissim-
7MCC has a range of [-1,1], where -1 specifies a totally incorrect binary classifier, while 1 specifies a totally correct binary classifier.
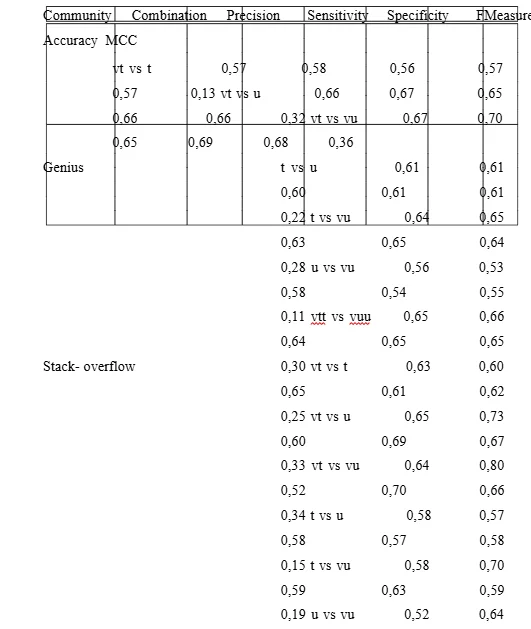

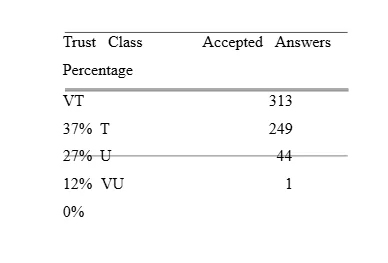
Clarity of both classes, the classes trusted and untrusted are relative near located to each other, which is reflected by the performance decreased be- tween these two classes specially in Stakoverflow (from 69% to 65% and 70% to 63% as F-measures of Genius and Stackoverflow respectively). This can be observed of more clearly in the relative limited performance measures of the combination untrusted and very untrusted in both online communities. In case of Stackoverflow, we investigate the distribution of answers that are marked as accepted by users. Accepted answers are located by 37%, 27%, 12% and 0% in the classes Very Trusted, Trusted, Untrusted and Very Untrusted, respectively as illustrated in Table 7. This is a one more evidence that high trust classes provide high quality content and that the classification based on the trust model is correct.
6. Discussion
This study investigates short-texts in the forms of interpretations and posts gained from the online communities Genius and Stackoverflow.
These short-texts were classified in terms of trust by our trust model based on its meta data. To answer our research questions, we applied syntactic analysis using a NLP approach combined with several readability indexes. Despite achieving some indications of the content difference of each class such as verbs and nouns frequencies, relation triples, number of complex words etc. due to the nature of short-text these indications cannot apply as strong evidences to distinguish the content. However, the RF classifier, based on BoW model as features, establishes such evidences.

6.1. Natural Language Processing
The experiment carried out represents a series of attributes that contains remarkable references to the differentiation of the short texts contained in the trust classes. The oblique line indicates the linear relationship represented by the attributes having the averages of numSentences, numWords, numSyllables and uniqueWords. However, these attributes include relatively high standard deviations, in addition to the numComplex Words attribute, which enables them to hardly predict a trust class of short texts. While in most of the cases, all readability indexes and the attributes wordsPerSentence, perComplexWords, SyllablesPerWord have an irregular distribution, which makes them unsuitable for trust prediction. The following Figures [4 to 13] illustrate an overview of some attributes examined. This pre-analysis includes exploring several PoS and readability indexes as features of short-text classified in the trust classes. Despite indications that could be able to predict trust class of a short-text given, we could not establish enough evidences on the influence of such features on trust. Thus, it is hard to consider these features in the trust model proposed, for which, we looked for another way to investigate the correlation between a short-text and the trust class.
6.2. RF classifier using BoW Model
The performance measures, resulted of both online communities Genius and Stackoverflow, show an average of accuracies 62% and 61% respectively and can be applied to recognize the texts of different qualities. This means that, the classification of the trust classes can be reconstructed to a certain degree based on its content. This can be used as a pre-process for the trust model to increase performances or in the case that meta data is not available. By considering the different performance measures of the binary-classification of the trust classes, it clearly shows that the classifier performs linear with the logical distance of the trust classes. That is, it shows relatively low accuracy and F-measure by making decisions on combinations of trust classes that are logical close to each other e.g. the combination of Very-Trusted vs. Trusted, Untrusted vs. Very-Untrusted or even Trusted vs. Untrusted8. While it performs better on the combinations of consisting of trust classes that have logical long distance between each other e.g. Very-Trusted vs. Very-Untrusted, Very-Trusted vs. Untrusted. In addition, the results show that the accepted-answers in Stackoverflow corpus are distributed according the trust degree of each class. That is, the higher the trust degree, the higher the percentage of the accepted-answers can be found; the percentages of accepted-answers are 37%, 27%, 12% and 0% in the trust classes Very-Trusted, Trusted, Untrusted and Very-Untrusted respectively.
6.3. Theoretical Contribution
Our investigation on text complexity and lexical analysis is consistent with the Information Manipulation Theory (IMT), presented in the next sub- section 6.4. The IMT uses key words (i.e. clearly, accurate, relate to and representation), which are reflected in this study by examining the multiple readability indexes and the tokens (BoW) used in creating and providing information. Exploring the readability indexes such as FOG, KINCAID, ARI etc., which calculate the text complexity degree, addresses the quantity aspect of the IMT. While, the metrics, deployed in the trust model (e.g., authority and reader rating), imply consideration of relevance and presentation of information.
8only in case of Stackoverflow
Accordingly, this study follows the principle and supports IMT, which is widely considered as one of the most significant explanations for data manipulation in communication.
6.4. Information Manipulation Theory (IMT)
McCornack [28] developed that so-called Information Manipulation The- ory (IMT) that explores the behaviour during information providing. Ac- cording to Levine [29], IMT offers a multidimensional approach to the design of misleading messages and uses maxims as a framework for describing a variety of misleading message forms. The maxims that a truthful conversation includes are: Quantity represents a set of information a receiver is given in order to communicate clearly. That is, the degree of how much detail is de- livered to the receiver to get idea about the information transferred. Quality refers to which extend is an information factual and accurate. Relevance refers to whether the provided information is related to the situation or topic of the conversation, and manner that considers information representation rather that the actual information itself.
6.5. Managerial Implication
Online communities can get benefit from our approach for reviewing the information provided on their platform. The first experiment based on Natural Language Processing (NLP) provides metrics such as verbs and nouns frequencies, relational triples and number of complex words that can be used as a guideline for users to improve the style of their content. On the one hand, an online community can evaluate the quality of contributions based on such metrics and then perform the appropriate actions (improve, return or remove). The second experiment with the Random Forest Classifier (RF), based on the Bag-of-Words (BoW) model, performs well and is able to identify content in terms of trustworthiness. This supports content filtering and reduces the overhead of low-quality content. Identifying high-quality content will improve the offering of an online community and increase the likelihood of users viewing it as a source of high-quality content.
7. Limitation and Future Scope of Research
The nature of the short texts means that, machine learning is limited as compared to such studies of ”long” texts. In the case of online communities and especially social media, the short texts are usually informal and noisy ( words in other languages, shortcuts, tokens, etc.). This makes the problem that needs to be addressed as it becomes much more complex. Our further work will explore the possibility of developing a method that maps informal text into formal text by determining and replacing the meaning of the noises used by the user. In terms of the structure and writing style of the text, it can be a similar approach to improve the short text by modification, without additions that could change its meaning.
Reference List
[1] X. Lin, Y. Li, X. Wang, Social commerce research: Definition, research themes and the trends, International Journal of Information Manage- ment 37 (2017) 190–201.
[2] N. Misirlis, M. Vlachopoulou, Social media metrics and analytics in marketing–s3m: A mapping literature review, International Journal of Information Management 38 (2018) 270–276.
[3] M. Mart´ınez-Rojas, M. del Carmen Pardo-Ferreira, J. C. Rubio-Romero, Twitter as a tool for the management and analysis of emergency situa- tions: A systematic literature review, International Journal of Informa- tion Management 43 (2018) 196–208.
[4] X. Cheng, S. Fu, G.-J. de Vreede, Understanding trust influencing fac- tors in social media communication: A qualitative study, International Journal of Information Management 37 (2017) 25–35.
[5] L. V. Casalo, C. Flavian, M. Guinal´ıu, Relationship quality, community promotion and brand loyalty in virtual communities: Evidence from free software communities, International journal of information management
[6] N. Pogrebnyakov, E. Maldonado, Didnt roger that: Social media mes- sage complexity and situational awareness of emergency responders, In- ternational Journal of Information Management 40 (2018) 166–174.
[7] R. Flesch, A new readability yardstick., Journal of applied psychology
[8] S. E. Schwarm, M. Ostendorf, Reading level assessment using support vector machines and statistical language models, in: Proceedings of
[9] R. Barzilay, M. Lapata, Modeling local coherence: An entity-based approach, Computational Linguistics 34 (2008) 1–34.
[10] J. Al Qundus, Technical Analysis of the Social Media Platform Genius, Technical Report, Freie Universitt Berlin, 2018.
[11] W. He, S. Zha, L. Li, Social media competitive analysis and text mining: A case study in the pizza industry, International Journal of Information Management 33 (2013) 464–472.
[12] R. Rekik, I. Kallel, J. Casillas, A. M. Alimi, Assessing web sites quality: A systematic literature review by text and association rules mining, International Journal of Information Management 38 (2018) 201–216.
[13] A. Gandomi, M. Haider, Beyond the hype: Big data concepts, methods, and analytics, International Journal of Information Management 35 (2015) 137–144.
[14] J. L. Solka, et al., Text data mining: theory and methods, Statistics
[15] A. Chalak, Linguistic features of english textese and digitalk of iranian efl students, Research in Applied Linguistics 8 (2017) 67–74.
[16] C. Jia, M. B. Carson, X. Wang, J. Yu, Concept decompositions for short text clustering by identifying word communities, Pattern Recognition
[17] B. Sriram, D. Fuhry, E. Demir, H. Ferhatosmanoglu, M. Demirbas, Short text classification in twitter to improve information filtering, in: Proceedings of the 33rd international ACM SIGIR conference on Re- search and development in information retrieval, ACM, pp. 841–842.
[18] B. Vijay, D. D. Rao, Improving accuracy of named entity recognition on social media, IJSEAT 5 (2017) 809–814.
[19] Y. Rao, H. Xie, J. Li, F. Jin, F. L. Wang, Q. Li, Social emotion classifica- tion of short text via topic-level maximum entropy model, Information
[20] A. Todirascu, T. Francois, D. Bernhard, N. Gala, A.-L. Ligozat, Are cohesive features relevant for text readability evaluation?, in: 26th In- ternational Conference on Computational Linguistics (COLING 2016), pp. 987–997.
[21] V. Hatzlvassiloglou, J. L. Klavans, E. Eskin, Detecting text similarity over short passages: Exploring linguistic feature combinations via ma- chine learning, in: 1999 Joint SIGDAT conference on empirical methods in natural language processing and very large corpora.
[22] M. Heilman, K. Collins-Thompson, J. Callan, M. Eskenazi, Combining lexical and grammatical features to improve readability measures for first and second language texts, in: Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference, pp.
[23] E. Pitler, A. Nenkova, Revisiting readability: A unified framework for predicting text quality, in: Proceedings of the conference on empirical methods in natural language processing, Association for Computational Linguistics, pp. 186–195.
[24] J. Al Qundus, A. Paschke, Investigating the effect of attributes on user trust in social media, in: International Conference on Database and Expert Systems Applications, Springer, pp. 278–288.
[25] M. Klassen, N. Paturi, Web document classification by keywords us- ing random forests, in: International Conference on Networked Digital Technologies, Springer, pp. 256–261.
[26] M. R. Berthold, N. Cebron, F. Dill, T. R. Gabriel, T. Kotter, T. Meinl, P. Ohl, K. Thiel, B. Wiswedel, Knime-the konstanz information miner: version 2.0 and beyond, AcM SIGKDD explorations Newsletter 11 (2009) 26–31.
[27] Q.-S. Xu, Y.-Z. Liang, Monte carlo cross validation, Chemometrics and
[28] S. A. McCornack, Information manipulation theory, Communications
[29] T. R. Levine, Dichotomous and continuous views of deception: A re- examination of deception ratings in information manipulation theory, Communication Research Reports 18 (2001) 230–240.



- 24/7 Customer Support
- 100% Customer Satisfaction
- No Privacy Violation
- Quick Services
- Subject Experts