Card Skimming Detection
E-commerce
E-commerce for most organizations, corporations and government departments, it has become a vital method to improve efficiency in global business. The quick purchase with the online credit card (Scaife, Peeters and Traynor, 2018) is a big reason for the growth of e-commerce. In talking about money transfers, we can also take financial manipulation into account. Financial fraud is a deliberate crime where fraudsters profit by denying the right or benefit of a victim. As credit card purchases became the most common payment method in recent years, fraud has grown rapidly. Businesses and public agencies face significant risk, given that fraud causes significant losses. (Scaife, Peeters, and Traynor, 2018) claims global credit-card, default- and prepay-card fraud losses amounted to $16,31B in 2015. According to statistics by Abdallah et al. (2016) have also shown that the gross loss of fraud in 2018 was four per cent higher than that for 2015. As seen in Figure 1, 2012 was the total fraud amount at $5.6b, and 2018 saw an overall loss of $9.1b, about two-fifths of the total. Card-Not-Present frauds comprise 70% of these frauds, 20% is falsified, and the remaining 10% is related to lost or stolen card damages (Ki and Yoon, 2018). Fraud responses may be split into disruptions, including fraud prevention at the source and intervention detection after the incident. Technology, like the address checking system and the card verification system, is in most cases used for deterring theft. If you need statistics dissertation help, it is essential to understand these financial dynamics.

Generally, rule-based filter and data mining avoidance techniques are (Adewumi and Akinyelu, 2017). Where fraud cannot be prevented, however, it must be identified, and appropriate action against fraud must be taken at the earliest opportunity. Fraud is detected to detect whether a transaction is lawful or not (Scaife, Peeters, and Traynor, 2018). In particular, in light of the vast traffic in transaction data, automatic fraud detection systems are needed, and human beings cannot manually search any transaction manually, whether it is fraudulent or not. This research is focused on the method of automated fraud detection with machine learning (Scaife et al., 2018).
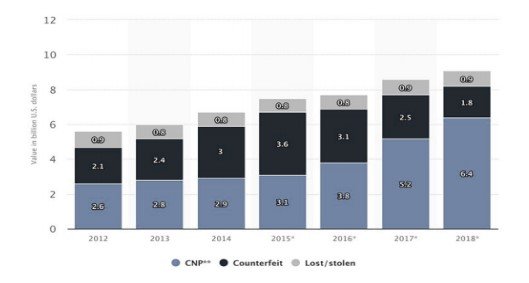
Figure 1: Lossless as an of Card fraud in the U.S. (Adewumi and Akinyelu, 2017)
Detection of Fraud
Transactions at the finishing point shall, as illustrated in Figure 1, be verified first or not. Some key requirements, such as adequate balance, correct personal identification number etc., are validated at the terminal phase. The predictive model classifies all real transactions as legitimate or counterfeit. Then every transaction is registered. Every fraudulent warning is reviewed, and feedback on the predictive success of the model can be provided (Adewumi and Akinyelu, 2017). This thesis covers only the statistical model.
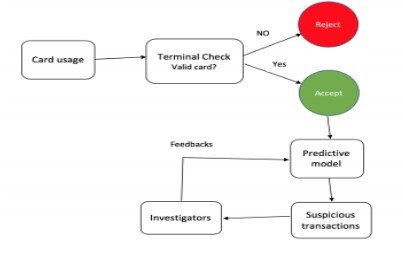
Figure 2. Fraud detection mechanism
Take a deeper dive into Global Reach in E-Commerce with our additional resources.
Fraud detection is not as easy as it may appear. The practice need to identify the method of machine learning to be employed, for instance controlled or uncontrolled learning, what algorithms to include; logistic regression and decision-making bodies and most specifically, how to handle a class imbalance problem (Popat and Chaudhary, 2018). The main challenge in the detection of crime is not just class imbalances. Another problem in the classification task (Ahmed et al., 2016) is the overlapping of genuine and corrupt classes due to limited transaction record information. Many machine learning algorithms do not work in those scenarios (Adewumi and Akinyelu, 2017).
A fraud detection model forecasts the class's existence (true or fraudulent) in a real-life scenario and warns researchers of the transaction most suspected. The inspectors then carry out a further investigation to provide input to improve the effectiveness of this system. However, this practice might be an overhead for investigators. If investigators checked only a few transactions in good time. The predictor model would only have a few reactions in such cases, typically leading to a less accurate model (Popat and Chaudhary, 2018). Lastly, because financial institutions often report their consumer details to the public due to secrecy problems, it is very difficult to locate the actual financial datasets. This is one of the biggest obstacles to science (Adewumi and Akinyelu, 2017) in fraud detection.
Objective
The main objective this investigation was to analyze credit card data and detect fraudulent data transactions using machine learning techniques. This data set is used for predictive analysis. The focus is on determining whether a transaction is classified by statistical models or illegal. Different sampling methods will be used to solve class inequality, and a range of algorithms to learn machines, such as logistical regression and random forests and XGboost, will be identified.
Literature review
Because credit card fraud has been an enormous challenge to the financial industry. Many financial institutions have invested heavily on building fraud identification mechanisms by bringing together human experts. Many scholars have worked actively to address the challenges posed by establishing an FDS, including a challenge of class imbalances, the overlap of classes, changes in fraud and so on. We will discuss some of the past research works in this area in this chapter.
Popat and Chaudhary (2018) recently examined two separate methods to identify fraud: a static approach where seasonally mostly monthly or annually training is provided for a detection model, and online approaches where the model is revised directly after the latest transaction results (Bhatia eta l., 2016). They have also shown a safer solution to online learning because fraud behaviour is changing time after time. Popat and Chaudhary (2018) have suggested that the better measurements to the identification of fraud should be average accuracy (AP), area under the curve, and Askari and Hussain (2017) concluded in another report that random forests are the safest solution to the challenge of screening fraud. When used for credit card transaction data resampled with Synthetic Minority Oversample technology, the closer neighbours, logical retrograde, and Naive Bays data study (Al Rawahi and Nair, 2015). The findings showed that K-nearest exceeded the two others. The reliability of the recall, consistency, safe rates, specificities, and maths association coefficient has been measured. The research suggested a graphic approach to developing the identification of a fraud scheme by (Askari and Hussain, 2017). A mutual deduction algorithm uses certain fraudulent transaction data to exert fraudulent leverage on a network. The current scheme for detecting fraud, APATE, has been retrofitted with several enhancements to its objective (Rajeshwari & Babu, 2016).
Rajeshwari & Babu (2016) suggested a single approach to the problem of detecting fraud. They also examined the possibilities of large-data technology in the field of fraud detentions using methods for big data, such as Cassandra, Spark and Kafka (SCARFF). The key emphasis has been placed on the fact that the detection of fraud requires a real-time setup. Due to the large volume of transaction data, a system with higher scalability, a tolerance to faults and accuracy is required. Rajeshwari & Babu, (2016) proposal from Domingos was the cost-sensitive MetaCost model. In his analysis, he said the cost is not the same for all errors of misclassification. The study further suggested a method for integrating the classification of the cost-reducing process that takes account of the error cost. The experiment concluded that, relative to other responsive classifiers, overall costs were reduced systematically using MetaCost (Patil and Dange, 2016). The database mining framework, which uses a neural network and is used for fraud detection, has been proposed by Rajeshwari & Babu (2016). The Hidden Markov Model (HMM), in which the client's spending habits are studied to identify fraudulent conduct, was suggested by Hegazy, Madian, & Ragaie (2016). Rajeshwari & Babu (2016) investigated various fraud detection algorithms, with the findings showing the possibility of filtering and ordering fraud cases decreasing fraud investigations. Bhatia et al. (2016) have also suggested another research analysis an automatic function engineering approach to reducing the highly wrong-positive rate normally seen in the results of the fraud forecast. Even as several pieces of research on various aspects of the detection of fraud, such as the monitoring of the cardholder activity, improved fraud detection time, the cost of misclassification, and different techniques of data mining, relatively few investigations have been carried out on methods for tackling the class disparity in the role of detecting fraud. This research, therefore, is rooted on conducting a predictive study of the identification process for credit card fraud, which focuses primarily on various strategies, including re-election, ensemble and hybrid approaches
Methodology
Data sets are a significant factor in the field of machine learning. Data collection, in particular in connection with credit card fraud, is one of the most challenging practices in the financial sphere. Worldline and (Universitat libre de Bruxelles) used the data set for a research project, which was originally used in this thesis (Tripathi et al. 2018) and was also puilt in Kaggle, an engineering dermatologist. It contains two-day archives of credit card transactions by European cardholders in September 2013. There are 284,807 transactions in the data set, of which only 492 are fraudulent. The data set is very unbalanced, as only 0.172 per cent of all transactions account for the positive class. A bar diagram in figure .1 is seen to show the unbalanced class distribution.
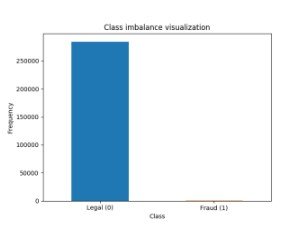
Figure 1. Classical distribution of Unbalanced class
The dataset includes the numerical values provided by a transformation of PCA 23. The original features were, however, not revealed because of the secrecy issue. There are 30 characteristics from which the main component analysis has produced features. PCA is a method of dimensional reduction where all of the initial variables are reduced into a smaller subset of variables. 'Number' and 'Time' are the only functions that have not been converted into major components (Sivakumar and Balasubramanian, 2015).
It is easier to imagine the data first in a predictive analysis before going through the implementation directly. The data can be visualized as the relationship between variables, as it corresponds to the reciprocal relationship between the variables. In general, the higher association characteristics with the answering variable have a greater effect during the workout process.
Data splitting
The entire data set for each experiment is divided up into 70 percent planning and a 30% test set. In this study, the test set was used, the setting of the hyparameter and the model training and we tested the trained model results with a test set. At the time of dividing data the same data were divided each time the program was launched, we described random seed (any random number).
Resampling Data
As previously mentioned, the dataset is highly unmatched. The number of real transactions exceeds the number of fake transactions. In this case, by using this data set for the training of the model, it tends to be biased toward legal transactions, which leads to a poor functioning model when evaluated on invisible information. To fix this problem, this study employed several re-equipment techniques, including Random Under-Sampling, Random Over-Equipment, SMOTE, Tomek Removal and an SMOTE-Tomek mixture. These resampling techniques have been applied to the training data separately to ensure that it is balanced.
10-fold cross-validation hyper-parameter tuning
Hyperparameter is an external model structure, the value of which cannot be determined from training data. The hyperparameter should not be confused with the model parameter as it can be determined during training time and an internal model state. The practitioner must manually specify its value because the hyperparameter is beyond the norm. However, the benefit must be properly assessed in advance in order to obtain optimum performance. The approach used to turn the hyperparameter is cross-validation techniques. it used K-fold cross-validation in particular to set K to 10.
Testing phase and training
Suppose there are 100 transactions, three of which are illegal and all of them lawful. Assume that the legal effect of all model transactions. The model accuracy is very high, in this case 97 percent. The truth is, however, that the model has not predicted all criminal transactions. In the predictive model, we do not want to overlook suspicious transactions because it is an error; we want a better callback score than it is.
Performance evaluation of selected models
After the hyper parameters have been set for each predictive model, this study sets the hyper parameters for each model. It then transferred the re-examined training set for each model as the training information. In the re-examined training results, the models thus learned various patterns. We used the test sample, divided before, to test the model's output when dividing the entire datase
Suppose 100 transactions exist, for example, three of which are illegal and all transactions are legitimate. Assume that all model transactions have a legal impact. The precision of the model is very high, 97 percent in this case. The fact is, however, that not all illegal transactions were predicted in the model. This study did not want to disregard suspicious transactions in the predictive model because it is a mistake to detect; we want better than possibly a callback score. However, it cannot ignore the accuracy rate since even though the transaction is not illegal, it did not want to forecast it neither. As the f1 scores are the harmonic mean of reminder and accuracy, it is a good metric for this issue.

Conclusion
The algorithm is also biased toward most samples as it provides the predictive model with the input data for highly unequalled class distribution. As a result, a fake transaction remains false as a true transaction. This study have taken a data-level approach to resolving this issue, which includes several reassessment methods, such as random undersampling, deletion of Tomek links, alteration of random sampling, SMOTE and removal of Tomek-like connections.
Take a deeper dive into Base Model With Sales Graph and Financial Reserves Analysis with our additional resources.
Reference
Abdallah, A., Maarof, M.A. and Zainal, A., 2016. Fraud detection system: A survey. Journal of Network and Computer Applications, 68, pp.90-113.
Adewumi, A.O. and Akinyelu, A.A., 2017. A survey of machine-learning and nature-inspired based credit card fraud detection techniques. International Journal of System Assurance Engineering and Management, 8(2), pp.937-953.
Adewumi, A.O. and Akinyelu, A.A., 2017. A survey of machine-learning and nature-inspired based credit card fraud detection techniques. International Journal of System Assurance Engineering and Management, 8(2), pp.937-953.
Ahmed, M., Mahmood, A.N. and Islam, M.R., 2016. A survey of anomaly detection techniques in financial domain. Future Generation Computer Systems, 55, pp.278-288.
Al Rawahi, M.M.K. and Nair, S.S.K., 2015, November. Detecting skimming devices in ATM through image processing. In 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA) (pp. 1-5). IEEE.
Askari, S.M.S. and Hussain, M.A., 2017, May. Credit card fraud detection using fuzzy ID3. In 2017 International Conference on Computing, Communication and Automation (ICCCA) (pp. 446-452). IEEE
Askari, S.M.S. and Hussain, M.A., 2017, May. Credit card fraud detection using fuzzy ID3. In 2017 International Conference on Computing, Communication and Automation (ICCCA) (pp. 446-452). IEEE.
Bhatia, S., Bajaj, R. and Hazari, S., 2016. Analysis of credit card fraud detection techniques. International Journal of Science and Research, 5(3), pp.1302-1307.
Bhatia, S., Bajaj, R. and Hazari, S., 2016. Analysis of credit card fraud detection techniques. International Journal of Science and Research, 5(3), pp.1302-1307.
Hegazy, M., Madian, A., & Ragaie, M. (2016). Enhanced fraud miner: credit card fraud detection using clustering data mining techniques. Egyptian Computer Science Journal (ISSN: 1110–2586), 40(03)
Ki, Y. and Yoon, J.W., 2018, January. PD-FDS: purchase density based online credit card fraud detection system. In KDD 2017 Workshop on Anomaly Detection in Finance (pp. 76-84). PMLR.
Patil, S.J. and Dange, A.S., 2016. Credit card fraud detection using hidden Markov model. International Journal of Engineering Science, 8359.
Popat, R.R. and Chaudhary, J., 2018, May. A survey on credit card fraud detection using machine learning. In 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI) (pp. 1120-1125). IEEE.
Popat, R.R. and Chaudhary, J., 2018, May. A survey on credit card fraud detection using machine learning. In 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI) (pp. 1120-1125). IEEE.
Rajeshwari, U., & Babu, B. S. (2016, July). Real-time credit card fraud detection using Streaming Analytics. In 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT) (pp. 439-444). IEEE.
Scaife, N., Peeters, C. and Traynor, P., 2018. Fear the reaper: Characterization and fast detection of card skimmers. In 27th {USENIX} Security Symposium ({USENIX} Security 18) (pp. 1-14).
Scaife, N., Peeters, C. and Traynor, P., 2018. Fear the reaper: Characterization and fast detection of card skimmers. In 27th {USENIX} Security Symposium ({USENIX} Security 18) (pp. 1-14).
Sivakumar, N. and Balasubramanian, R., 2015. Fraud detection in credit card transactions: classification, risks and prevention techniques. International Journal of Computer Science and Information Technologies, 6(2), pp.1379-1386.
Tripathi, D., Sharma, Y., Lone, T. and Dwivedi, S., 2018. Credit card fraud detection using local outlier factor. International Journal of Pure and Applied Mathematics, 118(7), pp.229-234.



- 24/7 Customer Support
- 100% Customer Satisfaction
- No Privacy Violation
- Quick Services
- Subject Experts