Machine learning
- 15 Pages
- Published On: 6-12-2023
INTRODUCTION
Learning as a generic process is about acquiring new, or modifying existing, behaviours, values, knowledge, skills, or preferences. Behaviourism, Cognitivism, Constructivism, Experientialism and Social Learning define the theory of personal learning, i.e. how humans learn. Machines rely on data contrary to what comes naturally to humans: learning from experience. At the very fundamental level of machine learning (ML) is a category of artificial intelligence that enables computers to think and learn on their own. It is all about making computers modify their actions to improve the actions to attain more accuracy, where accuracy is measured in terms of the number of times the chosen actions result from incorrect ones (Carleo et al., 2019). Machine learning is a multi-disciplinary field having a wide range of research domains reinforcing its existence. These are as shown in the following figure 1. The simulation of ML models is significantly related to Computational Statistics whose main aim is to focus on making predictions via computers (Liakos et al., 2018). It is also co-related to Mathematical Optimization which relates models, applications and frameworks to the field of statistics. Real-world problems have high complexity which makes them excellent candidates for application of ML. For students looking for data analysis dissertation help, understanding these foundational aspects of machine learning can provide a solid basis for research and application in various fields.
Machine learning can be applied to various areas of computing to design and programming explicit algorithms with high-performance output, for example, email spam filtering, fraud detection on the social network, online stock trading, face & shape detection, medical diagnosis, traffic prediction, character recognition and product recommendation amongst others. The self-driving Google cars, Netflix showcasing the movies and shows a person might like, online recommendation engines—like friend suggestions on Facebook, "more items to consider" and "get yourself a little something" on Amazon, and credit card fraud detection, are all real-world examples of the application of machine learning (Athey, 2018).

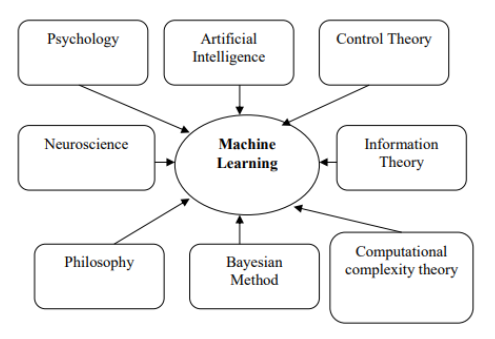
Machine learning
Machine learning, artificial intelligence, and other modern statistical methods are providing new opportunities to operationalise previously untapped and rapidly growing sources of data for patient benefit (Butler et al., 2018). Despite much promising research currently being undertaken, particularly in imaging, the literature as a whole lacks transparency, clear reporting to facilitate replicability, exploration for potential ethical concerns, and clear demonstrations of effectiveness. Among the many reasons why these problems exist, one of the most important (for which we provide a preliminary solution here) is the current lack of best practice guidance specific to machine learning and artificial intelligence (Carleo et al., 2019).
The field of machine learning has accrued experience across a broad number of areas, and there is now a push for developing a more formal theory of learning. While we are still a long way from this general aim, fundamental principles exist on which such a theory should be based: statistics, the representation and utility of knowledge, computational complexity, man-machine interaction, and the psychology of learning (Carleo et al., 2019). Perhaps the first attempt to encompass some of this broad spectrum in a formal theory was made by Valiant in his "theory of the learnable".Valiant argued that a theory of learning should show classes of concepts are le unable in the context of an appropriate information gathering mechanism and a reasonable number of steps (Sammut, & Webb, 2017). The best-known instance is Valiant's model for learning logical concepts from random examples (Butler et al., 2018). 1 shall refer to this as the Valiant model, which is distinct, from his general framework. The Valiant model has subsequently been developed by several researchers to yield an impressive array of results and research tools.
Amsterdam suggested several extensions to the model, incorporating queries and learning approximate representations of a concept, and criticised the model for its restricted scope. The Valiant model is becoming recognised as a standard for formal learning theory and several extensions exist. But if it is to be a standard, we should heed Amsterdam's criticisms and first consider just how well the Valiant model handles its intended task, without extensions and considering only its (admittedly restricted) current scope (Carleo et al., 2019). This paper does just that; the paper is a critique of the statistical component of the Valiant model. The Valiant model is primarily concerned with the logic induction problem (Sammut, & Webb, 2017). For example, suppose for discussion that we are designing a system to plan the routing of sheet steel through a large manufacturing plant. To decide whether to use the annealing process or not, a product may be classified by several attributes that together uniquely determine whether the process should be used. That is, there is known to exist a necessary and sufficient (logical) definition of the "annealing" class given in terms of attributes, this is the classification rule we hope to approximate (Jaeger, Fulle, & Turk, S2018). The only induction theories that address the use of preference (or "bias") specifically are Bayesian statistics and its logarithmic counterpart, the minimum description length (MDL) method. These answer Mitchell's concerns [Mitchell, 1980] in mathematical detail: how "bias" is required, how it can be implemented (as a measure of belief), and how it affects the logical induction process (Piccialli et al., 2019) .
Data Science problems and Machine Learning
Machine learning is required to make the computers sophisticatedly perform the task without any intervention of human beings based on learning and constantly increasing experience to understand the problem complexity and need for adaptability (Elbadawi et al., 2020). Tasks performed by Human Beings: There are lots of tasks performed on day to day basis by human beings, but the main concern is that to perform the tasks perfectly and to perform under the well-defined program. Examples: Cooking, Driving, Speech Recognition (Carleo et al., 2019). Tasks beyond Human Capabilities: Another category of tasks includes which can be effectively done by machine learning is an analysis of large and complex data sets like Remote Sensing, Weather forecasting, Ecommerce, Web search etc. With large amounts of data, it becomes complex for human beings to predict meaningful data.
Machine learning has proven capabilities to inherently solve the problems of data science. (Carleo et al., 2019) define data science as, "a concept to unify statistics, data analysis, machine learning and their related methods to understand and analyze actual phenomena" with data". Before taking to problem-solving, the problem must be categorized suitably so that the most appropriate machine learning algorithm can be applied to it (Kaur & Kumari, 2020). Any problem in data science can be grouped in one of the following five categories as shown in Figure 2.

State of art
Algorithms for machine learning are rising. New strategies that overdue today's leading algorithms are introduced every year. Some are minor developments or established algorithms are mixed and others are freshly built and lead to incredible advancements. There are also many excellent posts for many methods describing the theory and some even give code and guide implementation (Islam et al., 2019). None of the leading algorithms has yet provided an outline, so the proposal was focused on data collected to present the best algorithms per tasks (performance scores are used). Naturally, several more tasks remain and not all tasks can be submitted. We tried to pick the most common fields and activities and hope that will help you understand them better. Computer vision, natural language processing and speech recognition are the main topics on which this essay will depend (Peñalvo et al., 2018).
Computer Vision
Computer Vision is one of machine learning's most sought and popular areas. It is used for solving several day-to-day challenges and includes you in many applications, the vision of self-driving cars being the most common today (Mohan et al., 2019) . The work we will look at is semantic segmentation, recognition of images and identification of objects (Bandyopadhyay & Dutta, 2020).
In Computer Vision, the development of many copies of the same image with various resolutions is a common approach to increasing precision (Mishra et al., 2018). This creates a Pyramid since the smallest picture is arranged as the top layer and the largest picture as the bottom layer. This is a pyramid of the function network. Two-way means there isn't just a top-down approach, but a bottom-up approach simultaneously (Mishra et al., 2018). Any two-way path is used to serve the BiFPN as a network layer. It helps to increase precision and speed (Mishra et al., 2018).
Sentiment Analysis
Sentiment Analysis is a Text Mining field that is used for the understanding and classification of emotions in text data. BERT, which reached a precision of 55.5% in the 2019 SST-5 fine-grain classification dataset, is currently one of the best algorithms. Google AI Team posted the original article (Mishra et al., 2018). BERT reflects transformer bidirectional encoder representations and offers two-way transformer technique instruction. Transformer technology is an attention paradigm that has historically been applied to language processing only in one way. To parse a left-to-right or right-to-left file (Musumeci et al., 2018).
Language Modeling
The GPT-2 models have two phrases about a herd of unicorns that lived in the Andes. The GPT-2 model created an awesome story and the work is based on a calculation of the following words or letters. One of the most popular Algorithms can be found in Megatron-LM in Language Modeling (Ucci et al.,2019). The Nvidia team unveiled the blueprint and paper for the first time in 2019. On 8300 billion parameters a GPT-2-like model was educated. The existing state of the art score of 15.8 should be lowered to just 10.8 test perplexity (Tanveer et al., 2020). The transformer network is used for the model. A transforming layer consists of an attention block and a two-layer multi-layer sensor throughout their work (MLP). The parallel model is used in each of the blocks. This leads to contact elimination and keeps GPUs measured. The GPU calculations are doubled to increase the model rpm.
Semantic Segmentation
Semantic segmentation can be used as a pixel-level interpretation of image structures and elements. Semantic segmentation methods aim to predict the structures and artefacts in an image. Semantic segmentation of a street scene as seen below to provide a clearer understanding:

Modern machine learning
Supervised Learning
This style of learning is sometimes called example learning. A definition or a function that is the description of a model has to be taught in supervised training. The method has a variety of examples in particular (Xie et al., 2018). The effect of the goal function is also available for any of these instances. The framework needs to evaluate the model's definition based on the feature performance (Nilashi et al., 2017). For assessment usage, a subset of data (training set) is generated for a model, while the remaining data are used to determine the model developed (test set). In supervised machine learning, classification and regression are known for two learning tasks. The classification includes the building of projection models for discreet functions while regressions contribute to the building of forecast models for continuous functions. Machine learning strategies are the most widely supervised:
Learning definition. The cognitive structure includes examples (positive examples) or which do not form part of the definition (negative examples) (class). Then, a simplified definition of the term is asked for in the framework to be determined based on this description for possible situations (Kadhim, 2019).
• Induction Tree Designation or Determination. Methods of classification or tree decision-making are common and are used to estimate discreet target functions. These methods create tree structures which reflect the training data graphically. The biggest benefit of decision-making bodies is their simple understanding (Nilashi et al., 2017). Decision trees may also be depicted as laws "if-then."
• Rule instruction. Regulatory learning consists of triggering rules known as "if-then rules." For approximating discrete goal functions, classification rules are used.
• Simple learning case. Data are saved in their raw format in this method of learning. The machine analyses the relation between the current case and any stored example when it is called to determine a new case. This style of research is often called lazy learning since the method of learning is delayed before a new case emerges (Nilashi et al., 2017).
• Writing from Bayesian. This style of learning is based on the theorem of Bayes and includes approaches using probabilities. In the context of initial probabilities, current information may be integrated (Sarkar et al., 2019).
• Return linear. Linear regression is a method to define an objective with a variety of other variables associated with linearly. The spectrum of the goal function must be an interval constant.
Unsupervised Learning
This style of learning is sometimes called retrospective learning. Unattended learning allows the system to identify certain patterns (i.e. clusters) based only on the typical properties of the case, without understanding how many patterns or even whether there are (Sarkar et al., 2019). The following are the key unregulated strategies of machine learning:
• The Law of Mining Association: Association rule mining was developed in 1993 and has contributed a lot to the database research field. It has been implemented as a research tool for business baskets. Regulations for partnerships include the effects of type A B. The above rule is translated as implying that if item A appears in a basket, item B appears in the same basket too (Sarkar et al., 2019).
• Pattern mining sequential: Sequential pattern mining is about learning from structured knowledge. Normally, the order is temporary. It also has some submissions from the database analysis field and was recommended as an addition to the association legislation mining.
• Clustering. Clustering is the discovery technique of clusters of examples to render as close as possible examples that belong to the same cluster, whereas examples belonging to various clusters are as distinct as possible (Duraipandian, 2019).
Applications
In diverse areas of operation, deep learning has been broadly applied. Some of the most common applications include medical diagnostics, analysis of credit risk, consumer identification, market segmentation, target targeting, retail and detection of fraud (Sarkar et al., 2019). In recent years new data were available and thus new domains were generated in which machine learning was feasible thanks to numerous scientific developments and development initiatives such as the completion of the Human Genome Project and the evolution of the internet. Some of these new applications include biological sequences, text literacy, and learning in diverse settings like the internet (Duraipandian, 2019).

Similar success has been closely followed in molecular biology in the last decades by the exponential progress of computer science. In the processing and study of biological data, the use of electronic instruments has undeniably boosted, producing one of the highest research fields, including bioinformatics. Great parts of biological data involving the use of statistical methods for interpretation are expressed in biological sequences (Sarkar et al., 2019). The broad sequence size of the data and the many potential characteristics are key causes of the urgent methodologies for interpreting such data efficiently and supplying precise and reliable information to the domain expert. The machine learning area offers biologists a broad variety of resources for analyzing these results (Duraipandian, 2019). Many methods of machine learning to classify unique biological sequence segments were suggested. Neural networks, Bayesian classificatory, decision processing bodies and Vector Support Machines are among the more general. Algorithms for sequence recognition display an output balance between improved sensitivity (ability to recognize true positives) and decreased selectivity (ability to exclude false positives). But conventional machine learning methods, as (Sarkar et al., 2019), cannot be extended to these kinds of recognition problems directly. The current methods also need to be tailored to such problems. Efforts have been made to address this issue by creating features and choosing the function. The use of algorithms in the community of structurally connected biological sequences is another master apprenticeship (Kadhim, 2019).
Take a deeper dive into Leveraging Technology in the Tourism Industry with our additional resources.
Reference
Athey, S. (2018). The impact of machine learning on economics. In The economics of artificial intelligence: An agenda (pp. 507-547). University of Chicago Press.
Bandyopadhyay, S. K., & Dutta, S. (2020). Machine learning approach for confirmation of covid-19 cases: Positive, negative, death and release. medRxiv.
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O., & Walsh, A. (2018). Machine learning for molecular and materials science. Nature, 559(7715), 547-555.
Carleo, G., Cirac, I., Cranmer, K., Daudet, L., Schuld, M., Tishby, N., ... & Zdeborová, L. (2019). Machine learning and the physical sciences. Reviews of Modern Physics, 91(4), 045002.
Duraipandian, M. (2019). Performance evaluation of routing algorithm for Manet based on the machine learning techniques. Journal of trends in Computer Science and Smart technology (TCSST), 1(01), 25-38.
Elbadawi, M., Castro, B. M., Gavins, F. K., Ong, J. J., Gaisford, S., Pérez, G., ... & Goyanes, A. (2020). M3DISEEN: A novel machine learning approach for predicting the 3D printability of medicines. International Journal of Pharmaceutics, 590, 119837.
Islam, M. M., Nasrin, T., Walther, B. A., Wu, C. C., Yang, H. C., & Li, Y. C. (2019). Prediction of sepsis patients using machine learning approach: a meta-analysis. Computer methods and programs in biomedicine, 170, 1-9.
Jaeger, S., Fulle, S., & Turk, S. (2018). Mol2vec: unsupervised machine learning approach with chemical intuition. Journal of chemical information and modeling, 58(1), 27-35.
Kadhim, A. I. (2019). Survey on supervised machine learning techniques for automatic text classification. Artificial Intelligence Review, 52(1), 273-292.
Kaur, H., & Kumari, V. (2020). Predictive modelling and analytics for diabetes using a machine learning approach. Applied computing and informatics.
Liakos, K. G., Busato, P., Moshou, D., Pearson, S., & Bochtis, D. (2018). Machine learning in agriculture: A review. Sensors, 18(8), 2674.
Mishra, P., Varadharajan, V., Tupakula, U., & Pilli, E. S. (2018). A detailed investigation and analysis of using machine learning techniques for intrusion detection. IEEE Communications Surveys & Tutorials, 21(1), 686-728.
Mohan, S., Thirumalai, C., & Srivastava, G. (2019). Effective heart disease prediction using hybrid machine learning techniques. IEEE Access, 7, 81542-81554.
Musumeci, F., Rottondi, C., Nag, A., Macaluso, I., Zibar, D., Ruffini, M., & Tornatore, M. (2018). An overview on application of machine learning techniques in optical networks. IEEE Communications Surveys & Tutorials, 21(2), 1383-1408.
Nilashi, M., bin Ibrahim, O., Ahmadi, H., & Shahmoradi, L. (2017). An analytical method for diseases prediction using machine learning techniques. Computers & Chemical Engineering, 106, 212-223.
Peñalvo, F. J. G., Benito, J. C., González, M. M., Ingelmo, A. V., Prieto, J. C. S., & Sánchez, R. T. (2018). Proposing a machine learning approach to analyze and predict employment and its factors. IJIMAI, 5(2), 39-45.
Piccialli, F., Cuomo, S., di Cola, V. S., & Casolla, G. (2019). A machine learning approach for IoT cultural data. Journal of Ambient Intelligence and Humanized Computing, 1-12.
Sammut, C., & Webb, G. I. (2017). Encyclopedia of machine learning and data mining. Springer.
Sarkar, S., Vinay, S., Raj, R., Maiti, J., & Mitra, P. (2019). Application of optimized machine learning techniques for prediction of occupational accidents. Computers & Operations Research, 106, 210-224.
Tanveer, M., Richhariya, B., Khan, R. U., Rashid, A. H., Khanna, P., Prasad, M., & Lin, C. T. (2020). Machine learning techniques for the diagnosis of Alzheimer’s disease: A review. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 16(1s), 1-35.
Ucci, D., Aniello, L., & Baldoni, R. (2019). Survey of machine learning techniques for malware analysis. Computers & Security, 81, 123-147.
Xie, J., Yu, F. R., Huang, T., Xie, R., Liu, J., Wang, C., & Liu, Y. (2018). A survey of machine learning techniques applied to software defined networking (SDN): Research issues and challenges. IEEE Communications Surveys & Tutorials, 21(1), 393-430.



- 24/7 Customer Support
- 100% Customer Satisfaction
- No Privacy Violation
- Quick Services
- Subject Experts